Introducere: Iluzia butonului „Șterge”
Când folosim ChatGPT, Claude sau Gemini, trăim cu o impresie confortabilă de control. Scriem un text (un „prompt”), AI-ul ne răspunde, și apoi, dacă dorim, ștergem conversația. În mintea noastră, odată ce am apăsat „șterge” sau am închis fereastra, textul nostru a dispărut în neantul digital.
Companiile care dezvoltă aceste modele ne spun ceva similar: „Nu vă faceți griji, nu păstrăm prompturile voastre la nesfârșit. Păstrăm doar niște date tehnice interne, niște ‘ecouri’ ale procesării, pentru a ne asigura că sistemul funcționează bine. Datele acestea sunt ilizibile pentru oameni.”
Până ieri, această explicație era suficientă pentru avocați și experți în securitate. Dar un nou studiu tehnic tocmai a aruncat în aer această presupunere, iar implicațiile juridice, în special pentru drepturile de autor, sunt uriașe.
Ce se întâmplă de fapt în „creierul” AI-ului? (Explicația simplă)
Să ne imaginăm că îi ceri unui pictor să reproducă „Mona Lisa”. Tu îi dai originalul (promptul), el pictează, și la final îți dă copia (răspunsul).
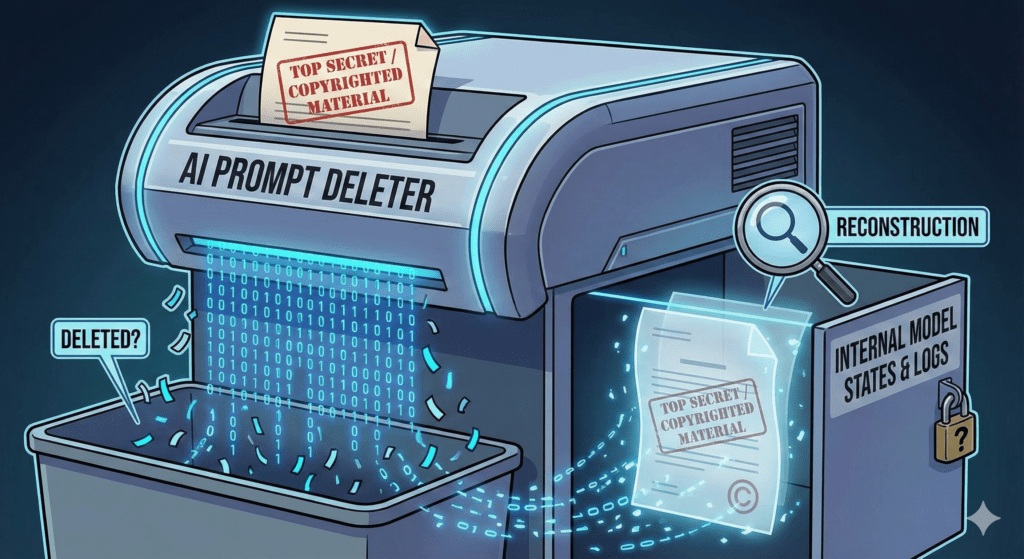
Procesul actual de „ștergere” funcționează cam așa: compania de AI promite că distruge originalul „Mona Lisa” pe care l-ai adus tu. Dar, în atelierul pictorului, rămân schițele preliminare, paleta cu exact aceleași combinații de culori folosite și amprenta exactă a tabloului în șevalet.
Aceste „schițe și palete” sunt ceea ce tehnicienii numesc „stări interne ale modelului” (hidden activations sau KV caches).
Marea descoperire: Schițele sunt la fel de bune ca originalul
Noul studiu demonstrează ceva ce părea imposibil: dacă ai acces la acele „schițe și palete” din atelierul digital al AI-ului, poți reconstrui „Mona Lisa” originală aproape perfect.
Cercetătorii au arătat că „ecourile” tehnice care rămân temporar în sistem în timp ce AI-ul gândește sunt atât de detaliate, încât conțin, codificat, textul exact pe care l-ai introdus.
De ce este acesta un coșmar pentru Drepturile de Autor (Copyright)?
Aici devine complicat. Să presupunem că o companie mare folosește un model AI intern pentru a analiza documente. Un angajat introduce în prompt un capitol întreg dintr-o carte protejată de copyright, sau un cod sursă secret aparținând unui concurent, doar pentru a cere un rezumat.
Compania are o politică strictă: „Ștergem prompturile imediat după utilizare pentru a nu încălca legea copyright-ului!”.
Conform noului studiu, această politică este acum inutilă dacă compania păstrează „datele tehnice interne” pentru monitorizare sau depanare (ceea ce aproape toate fac).
Dacă poți reconstrui materialul protejat de copyright din datele tehnice pe care le stochezi, din punct de vedere legal, este foarte posibil să se considere că încă deții și stochezi materialul original.
Nu mai poți spune „Nu am cartea originală, am doar niște date numerice ilizibile”. Dacă acele date numerice pot fi transformate înapoi în carte folosind un algoritm, atunci deții o copie neautorizată a cărții.
Cine are acces la aceste „umbre digitale”?
Este important de reținut: utilizatorul obișnuit de acasă NU poate face această reconstrucție. Nu poți extrage promptul original doar din răspunsul AI-ului.
Pericolul este la nivel de infrastructură. Accesul la aceste date interne îl au:
- Furnizorii de modele (OpenAI, Google, Microsoft etc.).
- Companiile care își găzduiesc propriile modele AI pe serverele lor.
- Atacatorii informatici (hackerii) care ar putea compromite aceste servere.
Dacă o companie stochează aceste „ecouri” tehnice în jurnalele de sistem (logs) pentru 30 de zile, înseamnă că timp de 30 de zile stochează, potențial, tot materialul protejat de copyright care a trecut prin sistem, chiar dacă „prompturile” au fost șterse.
Concluzie: Ce trebuie să se schimbe?
Această cercetare schimbă regulile jocului pentru departamentele juridice și de conformitate din corporații.
Vechea distincție dintre „conținutul promptului” (sensibil) și „telemetria tehnică” (sigură) a dispărut.
Companiile care cumpără servicii AI enterprise trebuie să înceapă să pună întrebări incomode furnizorilor: - „Stocați stările interne ale modelului (inference artifacts)?”
- „Dacă da, pentru cât timp?”
- „Înțelegeți că stocarea lor poate echivala legal cu stocarea conținutului original protejat de copyright?”
Contractele viitoare nu vor mai trebui să protejeze doar „prompturile și răspunsurile”, ci și „orice artefact tehnic derivat din prompt”. Până atunci, butonul „Șterge” este doar o promisiune goală.
The „Digital Echo”: Why Deleting Your AI Prompts Might Not Save You From Copyright Risks
Introduction: The Illusion of the Shredder
When enterprises use Large Language Models (LLMs), they often rely on a digital equivalent of a paper shredder. The policy usually looks like this: „We use the model to summarize this copyrighted book or analyze this proprietary code, and then we immediately delete the prompt.”
The assumption is simple: once the text is gone, the liability is gone. Companies differentiate between „User Content” (the prompt, which is sensitive and risky) and „System Telemetry” (technical logs, which are viewed as harmless data dust).
A groundbreaking new research paper has just shattered that assumption. It reveals that the „digital dust” left behind—the model’s internal processing states—can be swept up and reassembled into the original document.
The Science: The Blueprint Remains
To understand the risk, you don’t need a PhD in machine learning. You just need to understand the difference between the output and the process.
Imagine you ask an artist to paint a replica of a copyrighted photograph. You hand them the photo (the prompt). They paint it. Afterward, you take back the photo and destroy it. You think you’re safe.
But this new research shows that if you kept the artist’s preliminary sketches, their mixing palette, and the faint indentations on their easel (the inference artifacts), you could perfectly reconstruct the original photograph.
In technical terms, the „hidden activations” and „key-value caches”—data often stored for debugging or observability—encode the prompt so fully that it can be reverse-engineered.
The Copyright Trap: „Non-Readable” is No Longer a Defense
This creates a massive blind spot for Intellectual Property (IP) compliance.
Copyright law generally grants the owner the exclusive right to reproduce their work. If an organization holds a database of technical logs that can be algorithmically transformed back into a copyrighted novel, a competitor’s source code, or a leaked movie script, that organization is effectively storing unauthorized copies.
The defense of „We only store abstract vectors, not text” falls apart if those vectors are functionally equivalent to the text.
If you are preserving these artifacts for performance monitoring or safety evaluations, you might be inadvertently building a library of copyrighted material you thought you had deleted.
The „Reasonably Likely” Standard
Crucially, the paper notes that an average user cannot do this reconstruction from the chatbot’s final answer. However, model providers, self-hosting enterprises, and anyone with infrastructure access (including attackers) can.
This touches on a key legal concept often seen in data privacy (like the EDPB guidelines) but applicable here: Means of Reconstruction.
If the means to reconstruct the original text are „reasonably likely” to be used (e.g., by a system administrator or a hacker accessing the logs), the data is not anonymized. In the context of copyright, if the „copy” exists in a state that can be read with the right tool, it is still a copy.
The Takeaway for Enterprise Leaders
The comfortable line between „content” and „telemetry” has blurred. If you are responsible for AI governance or legal risk, here is your new reality:
- Observability is not Risk-Free: Storing long-term logs of internal model states is now a liability risk for both privacy (GDPR) and copyright.
- Update Your Contracts: Standard Data Processing Agreements (DPAs) usually cover prompts and outputs. They rarely mention „inference artifacts.” They need to.
- Ask the Hard Question: Ask your model provider: „Do you retain hidden states or KV caches? If so, can you guarantee they cannot be reverse-engineered to reveal our input data?”
Until providers can guarantee that these „digital echoes” are scrubbed, the delete button is just a suggestion, not a reality.